摘要:为解决线下传统调研难度大、成本高,以及网络访问固定样组调研和大数据调研样本代表性不足难以进行统计推断等问题,本文重点研究利用数据融合(Data Fusion)方法逐步搭建大数据调研、云Panel调研、传统线下调研三种方式融合贯通的新型调研模式。具体利用基于倾向得分匹配的样本匹配(Sample Matching)方法,将来自三种调研方式的样本及调查数据有效融合,创造三种调研方法相互结合、相互补充、相得益彰的新型调研方式,提高运作效率,提升调研质量。研究表明,基于倾向得分匹配的样本匹配方法可以实现不同调研方式的融合贯通,在实际市场调查中具备可应用价值。
关键词:大数据调研;云Panel调研;传统调研;样本匹配;倾向得分匹配
1引言
市场调研的三大核心问题可以归结为:第一,数据质量:包括控制抽样误差和非抽样误差,抽样误差主要强调的是样本代表性,非抽样误差指调查中所有其他因素带来的误差;第二,执行效率,调研项目成功与否很大程度上决定于项目响应率、问卷的回答率;第三、调查费用,即成本,市场调研行业就是在这三大核心问题上不断寻找着最优化的组合。而不论包括入户、街访的传统线下调研,还是网络迅猛发展下,利用基于样本招募的自有和外部网络访问固定样组的云Panel调研,以及大数据形势下应运而生的大数据调研,在面临这三大问题,寻找最优解时,各自体现出了突出的优势及不足。
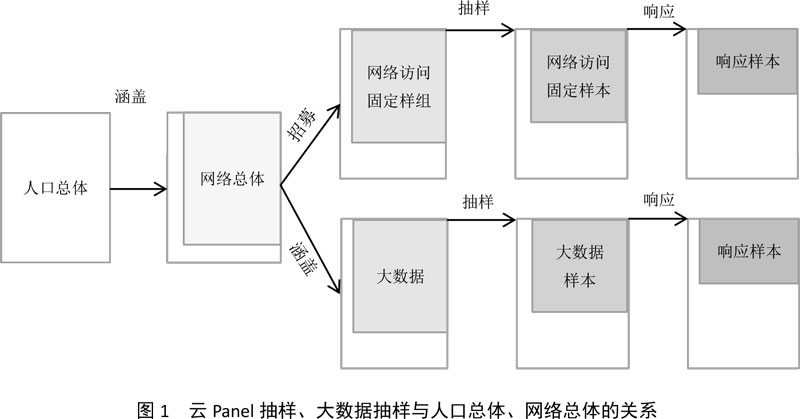
线下传统调查特别是入户调查,因遵循随机原则而使样本能够准确反映调查总体的信息。实际中,我们有很多推及总体的项目,比如电视观众满意度的项目、居民消费习惯调查基本上都是入户调查,最后要精准推及到全市、全省乃至全国的总体情况;再有,国内很多权威调研,比如居民收入水平调查,还需在入户调查前出具最为专业细致的抽样方案来保证样本的代表性,从而最终保障调查总体数据的准确可靠。可见样本数据是调研之本源,样本是偏的,调查结果无疑将出现不可忽视的偏误,所以统计抽样的重要性不言而喻。而网络调查所依托的网民群体目前来讲还不能代表总体,有相当一部分个体没有入样,很难实现真正意义上的“随机原则”从而保障良好的代表性。它们更适合应用在特定人群或者与互联网使用相关的调查中来提高样本代表性,所以其应用范围及应用深度均受到一定的阻碍。图1表示云Panel抽样、大数据抽样与网络总体、人群总体之间的关系。然而,随机样本的触达是非常困难的,入户调查会耗费大量的人力、物力、财力;而云Panel调研和大数据调研相较线下传统调研则非常高效、经济、便捷,并且大数据调研还有其更加突出的优势:渠道资源丰富、用户覆盖范围广、用户画像精准圈人,而且利用立体鲜活的人群画像能够更深层次的挖掘样本信息以获得更深层次的调查结论。
综述所述,这三种调研方式皆是尺有所短,寸有所长。那么,如何在保障数据质量的基础上,充分利用云Panel、大数据的调查优势,拓展其在市场调查中的应用,尽可能高效率、低成本、精准地执行我们的调研任务,是我们目前面临的挑战和亟待解决的问题。对此,我们将尝试利用数据融合技术中的样本匹配法将三种调研方式融合贯通,研究该方法在统计调查中的可应用性,这无论是对丰富调查抽样领域的研究,还是对解决市场调查中存在的实际问题均具有重要的学术意义和应用价值。
2大数据调研、云Panel调研、传统线下调研的融合贯通
本文主要研究利用数据融合(Data
Fusion)方法逐步搭建大数据调研、云Panel调研、传统线下调研三种方式融合贯通的新型调研模式。具体利用样本匹配(Sample Matching)方法,将来自三种调研方式的样本及调查数据有效融合,创造三种调研方法相互结合、相互补充、相得益彰的新型调研方式,提高运作效率,提升调研质量。
所谓样本匹配,通常被用于非随机化的观察性研究中,特别是在医学、生物学领域有着广泛的应用。目前,样本匹配方法已不乏应用于市场调查中的先例,国内外也有很多的文献支持,Rivers[1]2006
年首次提出样本匹配法(Sample Matching)是一种从非概率样本中选择代表性样本的新方法,特别适合于网络固定样组调查。Vavreck
和 Rivers[2](2008)针对美国国会选举研究,选用了一种基于距离函数的样本匹配法从云Panel中采集与美国社区调查文档中最近的匹配样本,通过匹配样本的数据进行估计,发现与传统的调查方法相比总体估计的均方误差(RMSE)更小。Eggers 和 Drake (2011) [3]采用一种基于频数匹配的样本匹配方法,从网络访问固定样组中选取了一个以美国综合社会调查数据为目标样本的匹配样本,最终利用匹配样本的调查数据进行总体推断。金勇进、刘展(2015) [4][5]在大数据背景下非概率抽样的统计推断问题中也探讨了基于样本匹配的抽样方法以及权数构造与调整的具体解决办法。
样本匹配法的核心思想是:首先,从包含一系列协变量(性别、年龄、教育程度、职业、收入等)的目标总体抽样框中抽样一个概率样本作为目标样本;其次,根据协变量信息,采取一定的匹配方法,从网络样本中抽取与目标样本对象最为近似的单元,称为匹配样本;最终,对目标样本混合匹配样本展开调查访问,获取调查数据进行整体估计。样本匹配法涉及很多种类型,诸如基于决策树的样本匹配、基于最近邻的样本匹配、基于预测均值的样本匹配、基于随机森林模型的样本匹配等,本文重点研究倾向得分匹配(Propensity
Score Matching)。倾向得分匹配具有将高纬度匹配降为一维的突出优势,极大降低了计算复杂度,是目前最流行的统计方法之一,因而受到广泛应用。
2.1倾向得分匹配
倾向得分匹配原本用于因果推论,倾向得分指的是被研究个体在控制可观察到的混杂变量的情况下,接受某种处理的条件概率[6]。首先指定协变量 Xi,将有无接受处理记作Di(接受时,Di=1 ;反之Di=0 ),则个体i 的倾向得分为:p(Xi)=P(Di=1|Xi)。倾向得分匹配就是假设个体 i 属于处理组,找到属于对照组的某个体 j ,使得个体 j与个体 i 的协变量或倾向得分取值最大程度相近,即 X i ≈X j 或p(Xi)≈p(Xj)[7]。
倾向得分匹配的目的是通过控制混杂变量的影响来有效规避选择性误差,从而保证因果结论的可靠性。网络抽样中也不可避免地因样本有不同的参与意愿和倾向产生选择性偏差,从而损伤样本代表性,因此这种方法特别适合网络样本的代表性抽样。这里我们定义,Di=1表示单元i在目标样本中,Dj=0表示单元 j 在网络样本中。目标样本每个单元 i 都有一些协变量(性别、年龄、教育程度等)组成的向量Xi=(Xi1,Xi2,…,Xip),p 为协变量的个数,网络样本中每个单元j拥有同样协变量组成的向量Xj=(Xj1,Xj2,…,Xjp)。匹配具体步骤如下:
2.1.1 估计倾向得分
估计p(Xi)=P(Di=1|Xi)主要选择参数估计(probit/
logit)或非参数估计来处理,结合现状来看,logit函数作为常用连接函数,主要把示性变量Di定义成因变量,协变量Xi定义成解释变量实现
Logistic回归模型。实践处理阶段,假定Xi全部完成中心变换,那么:

式中,0≤p(Xi)≤1。
2.1.2选择匹配样本
寻找与目标样本匹配的网络,通常两者之间的相似程度通过距离函数来定义,不同的距离函数定义规则产生不同的匹配方法,常用的匹配方法有最近邻匹配、卡钳与半径匹配、分层或区间匹配、核与局部线性匹配等。本文研究基于最近邻匹配(Nearest Neighbor Matching,NNM)[8]。
最近邻匹配是将两组样本中最近的一个或多个样本进行匹配的方法。样本间的距离可采取不同定义,如1-范数、2-范数、∞ -范数等。若一个样本匹配另一组与其距离最近的一个样本,这种方法称为单一最近邻匹配,若匹配另一组与其最近的多个样本,在估计模型中对多个样本赋予不同权重,这种方法称为多重最近邻匹配。根据匹配单元是否进行多次匹配可分为有放回的最近邻匹配和无放回的最近邻匹配,其区别在于,有放回的最近邻匹配允许给定的网络样本单元(Dj=0)匹配到多个目标样本单元(Di=1)。本文采取单一无放回最近邻匹配,距离定义如下:
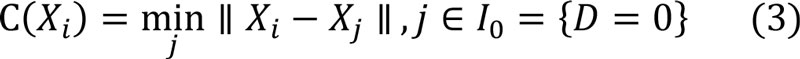
2.2基于样本匹配的调研方式融合贯通
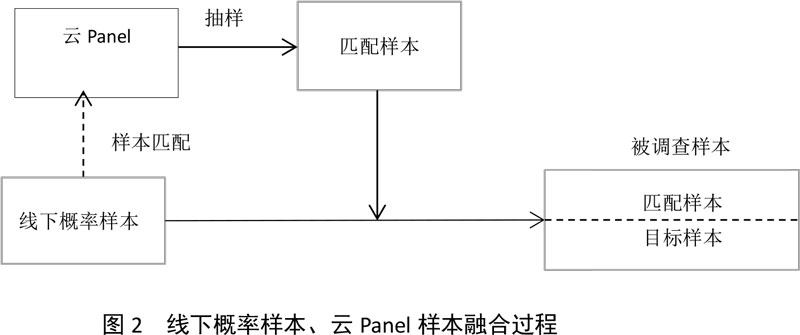
由2.1可知,匹配样本本质上近似于目标样本,不同调研方式的融合贯通则是指将匹配样本与目标样本相混合共同完成调查项目。云Panel调研和线下传统调研的融合贯通首先需在线下随机抽样部分样本进行访问调查,再根据当期线下概率样本为目标样本在云Panel中选择匹配样本,并邀请匹配样本完成调查,该过程展示如下图2:
云Panel调研和大数据调研的融合贯通,云Panel是以网民总体结构(CNNIC公布)为基础建立的,对网民总体具有一定代表性,那么为提高样本的代表性,我们以云Panel为目标样本在大数据样本中选择匹配样本,并邀请目标样本和匹配样本完成调查,该过程展示如下图3:
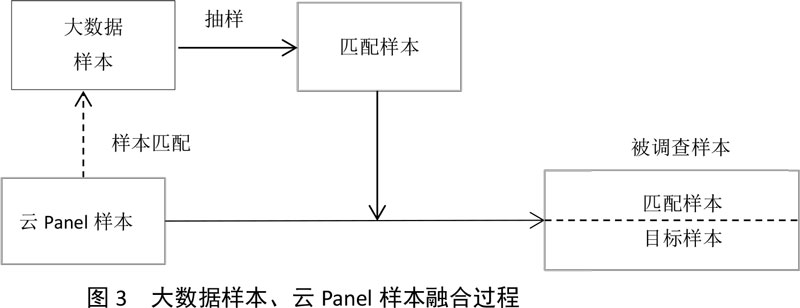
3实证研究
目前为止,我们已在不同类型的市场调查项目中进行了大数据、云Panel、传统调研间的融合贯通试验。试验过程均为,首先,通过两种调研方式简单随机抽样大样本量进行同期调查,并利用倾向得分匹配法以其中一种调研方式的样本为目标样本选取匹配样本;其次,进一步检验匹配后的目标样本与匹配样本在调查结果间是否存在统计学显著性差异。如果两者之间存在显著性差异,则一定程度上说明两种调研方式的样本不能相混合,反之,则说明两种调研方式的样本可以混合共同完成调研项目,可以融合贯通。
3.1
线下传统调研与云Panel调研的融合贯通
以*城市电视观众满意度研究为例,其是市场研究中的重要研究类型,通常以0分至100分的评分形式来反映对电视频道、栏目、主持人整体满意程度。线下入户调查样本600样本、同期云Panel样本750个。
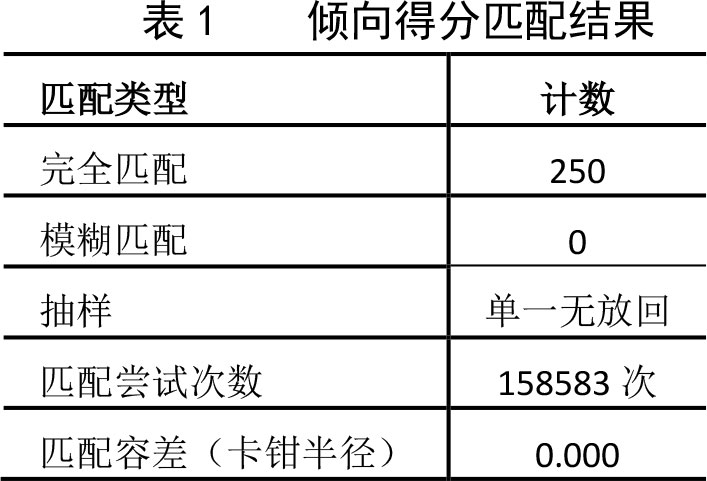
3.1.1倾向得分匹配
首先以线下概率样本为目标样本进行倾向得分匹配,我们这里选用的是最近邻法,单一无放回的一对一精确匹配的方法,匹配容差(卡钳半径)设为0,选取性别、年龄、教育程度、职业为协变量,精确匹配出的样本共计250对。倾向得分匹配具体实现过程在R中进行。特别地,对于样本匹配协变量的选择问题,由于不同类型的问题涉及的被调查群体的背景信息均存在或大或小的差异,我们不可能以偏概全地就使用某个或某几个固定的协变量来诠释所有被调查人群的背景情况,因此我们倾向于利用相应领域的专家咨询及行业经验来进行协变量的选择。
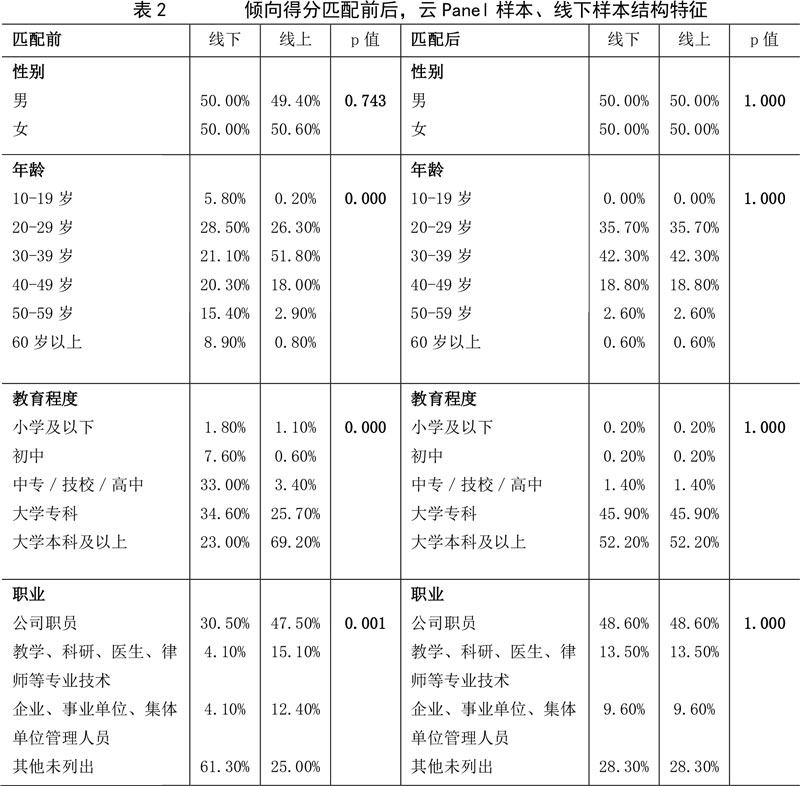
由下面表2可以看到,在样本匹配之前,网络访问固定样本中随机抽样的样本与线下概率样本在性别、年龄、教育程度、职业间均存在结构性差异;而在样本匹配后,匹配样本与目标样本在各个背景信息间的分布都更均衡可比。
可见,倾向得分匹配可以有效消除云Panel、线下样本在性别、年龄、教育程度、职业等混杂变量上存在的偏倚,使匹配样本与目标样本间不存在显著的结构性差异,此时匹配样本本质上可近似于线下概率样本。同时看到,匹配样本的分布取决于网络访问固定样本的分布,网络访问固定样本结构分布越均匀,匹配样本分布越均匀。目前网络访问固定样本尚未达到覆盖总体结构的水平,因此会对样本混合造成一定程度的影响,这种情况可以通过分层抽样的方法来解决,在此不作赘述。
3.1.2调查结果显著性差异检验
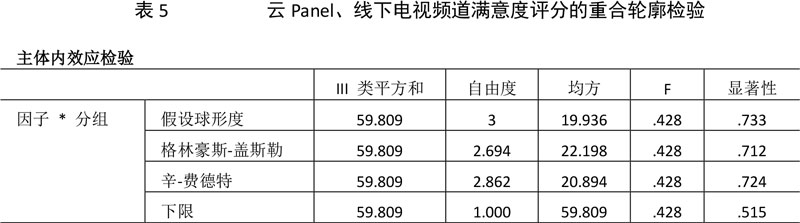
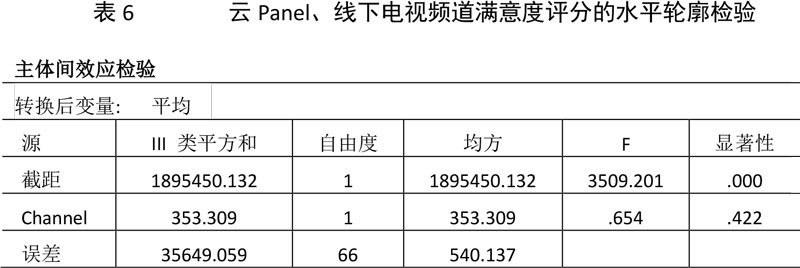
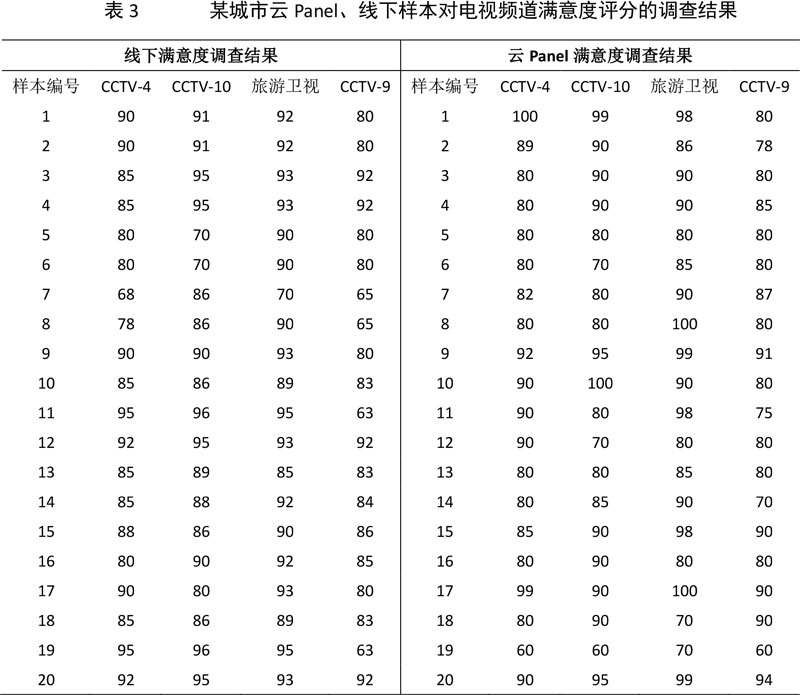
这里我们选用多元统计轮廓分析法对250对样本的调查结果进行平行轮廓、重合轮廓及水平轮廓检验。由于篇幅问题,这里仅对云Panel、线下各20个样本关于CCTV-4、CCTV-10、旅游卫视、CCTV-9的满意度评分进行展示。
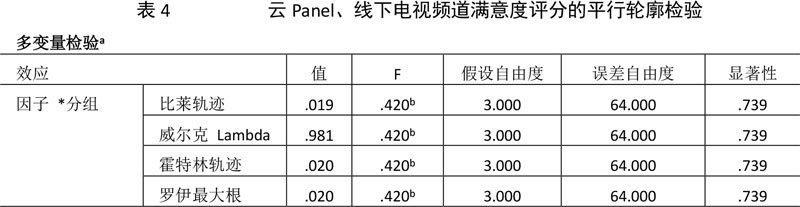
上表展示的是平行轮廓检验的结果,四种不同的检验统计量的p值均为0.739,表示在0.05的显著性水平下均通过检验,只有在通过平行轮廓检验的情况下才可进行重合轮廓检验。
上表展示的是重合轮廓检验的结果,四种不同的检验统计量的p值均远大于0.05,表示在0.05的显著性水平下均通过检验,只有在通过重合轮廓检验的情况下才可进行水平轮廓检验。
水平轮廓检验显示四种不同的检验统计量的p值均远大于0.05,表示在0.05的显著性水平下均通过检验。上述结果依然表明云Panel匹配样本与线下样本调查结果不存在显著性差异。
因此,云Panel中的匹配样本可以替代部分入户样本,实现与线下入户样本的有效融合,两种调研方式融合贯通。这样则可以在保障调查抽样具有良好代表性的基础上,充分利用云Panel的调查优势,高效高质量地完成调查项目。
3.2
大数据调研与云Panel调研的融合贯通
以*城市中高端白酒消费者研究为例,主要调查消费者中高端白酒的消费认知、消费渠道、消费场景等等。该项目通过外部大数据公司利用丰富的媒体资源、多维度的用户画像、以及场景化的投放快速而精准地触达336个样本,云Panel同期采集514样本。
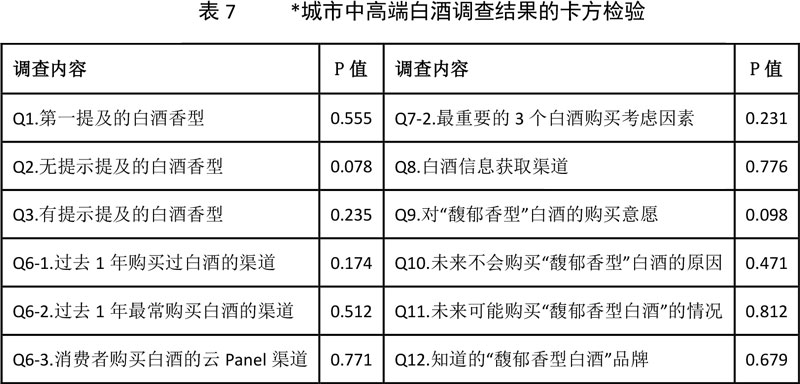
这里我们认为,云Panel是以网民总体结构(CNNIC公布)为基础建立的,对网民总体具有一定代表性,那么为提高样本的代表性,我们以云Panel为目标单元,通过倾向得分匹配成功匹配86对样本,并比较两种调研方式调查数据的显著性差异。表3结果说明,来自大数据的匹配样本与云Panel样本的调查结果已达到非常接近的程度,调查结果不存在显著性差异(这里应用卡方检验,调查结果双尾检验概率p值大于0.05,即在0.05的显著性水平下我们没有足够的理由拒绝原假设,即两者的调查结果不存在显著性差异)。
因此,大数据与云Panel的样本可以有效融合,两种调研方式融合贯通。这样可以充分利用大数据的突出优势,精准高效触达目标样本,更全面、深刻地挖掘用户特征、洞察研究内容,高效高质量地完成调查项目。
4结论
目前为止,本文通过样本匹配的方法尝试了线下传统调研和云Panel调研之间的融合贯通,以及大数据调研和云Panel调研之间的融合贯通。在保证抽样调查代表性的基础上着力解决线下传统调研面临的瓶颈,同时拓展大数据、云Panel在市场调研上广泛和深度应用,促使其在业界获得更为广泛的共识,逐步引导大家接受这种融合调研的方式。通过若干项目的试验论证,大数据、云Panel、传统调研融合贯通的方式不仅在市场研究理论上站得住脚,而且在调查实践中具备更强的可应用性。这种尝试对市场调查行业调查体系的良性发展具有重要应用价值,可以作为一种科学的调研方式在实际调查项目中进行尝试及推广。
投稿:王霄 李金玲 罗志亮 刘允强
央视市场研究(CTR)运作及样本中心
参考文献
[1]Rivers D.
Sample matching—representative sampling from internet panels [J]. Polymeric White Paper Series,2006.
[2]Vavreck L,Rivers D.
The 2006 cooperative congressional election study [J]. Journal of Elections,Public
Opinion & Parties,2008,18(4):35
-66.
[3]Rosenbaum P R,Rubin
D B. The central role of the propensity score in
observational studies for causal effects [J]. Biometrika,1983,70(1):
41 -55.
[4]刘 展 ,金勇进.大数据背景下非概率抽样的统计推断问题[J]. 统计研究,2016.3:11-17
[5]刘 展 ,金勇进.网络访问固定样本调查的统计推断研究[J]. 统计与信息论坛,2017.2:3-10
[6]Rosenbaum P R, Rubin D B. The Central Role of the
Propensity Score in Observational Studies for Causal Effects[J]. Biometrika,
1983, 70(1).
[7]刘 展 ,金勇进. 基于倾向得分匹配与加权调整的非概率抽样统计推断方法研究[J]. 统计与决策,2016.21:4-8
[8]Smith J A,Todd P E.
Does matching overcome La Londe’s critique of non-experimental estimators? [J].
Journal of Econometrics,2005,125(2):
305 -353.
|