关键词: Likert量表等级 电视节目 满意度 区分度 稳定性 有效性
内容摘要: Likert等级量表的应用,学者们在商品、服务满意度调查等多领域已有较为充分研究,但对于文化创意类产品如电视节目的满意度调查,且调查结果将被直接应用于连续性的季度或年度考核时,哪种量表最为适用,业界并无明确定论。本文选取2014年1-4月有播出的各卫星频道热门节目30个,分别采用五分制、 七分制、 十分制和百分制五对观众进行了满意度调查,利用调查数据试图分析出哪种量表对应用于考核管理需要的电视节目满意度调查更为有效。
ABSTRACT:The application of Likert Scaling. Scholars have
conducted relatively sufficient researches in satisfaction surveys of goods and
services. But there is not a widely used tool for the measurements of cultural
creative products such as satisfaction surveys of television programs, of which
the results will be directly applied to successive quarterly or annual
appraisals. Therefore, there is no conclusion as to which scale is the most
applicable. This article selects thirty popular programs broadcasting on the
satellite channels , respectively using five-point scale, seven-point scale,
ten-point scale and centesimal system in
audience satisfaction survey. By analyzing the survey data, the author
is trying to tell which scale is the most effective, especially in the
satisfaction survey of TV programs for the
program evaluation.
KEY
WORD: Likert Scaling, the survey of audience satisfacation , recognizability ,stability, validity
1 研究背景及问题提出
满意度调查普遍应用于各个领域,无论通过单个题项直接调查,还是通过多题项量表形式调查,目前最常使用的是Likert量表打分的方式进行。对于哪种等级量表最合适有效,学者在商品、服务满意度调查等多领域已有较为充分研究。代表性的研究有美国学者Cox在1980年回顾大量量表文献后认为:1)适用于任何情况的最优量表等级并不存在,分析量表精度必须考虑研究问题、研究对象等实际情况;2)相对于3级以上量表,2级和3级量表可收集到调查对象的信息过少;3)根据调查对象是否能合理选择中性中间点,而选择是否推荐使用具有中性中间点的量表;另外,应答选项的增加可一定程度减小中性中间点的被选比例;4)较多研究者的研究结论都支持:5级、7级、9级、10级量表的精度都较好,明显高于5级以下和10级以上量表的精度,且5-10级适用于多数情况。澳大利亚学者John在2002年和2008年两次研究中得到,5级、7级、10级、11级量表的数据都呈现负偏态和平阔峰分布,但量表之间在偏度和峰度并不存在显著性差异 。另外研究者还发现,不同人群的分辨能力也会影响到量表等级的选择。英国学者Eduardo等在2009年的流行病学研究发现,对于没有受过教育的人群,3级likert式量表的测量特性要好于5级。荷兰学者Borgers等认为,针对青少年和儿童的量表最佳等级为4级,应综合考虑调查对象的分辨能力、配合程度及调查内容的敏感性等情况,以决定如何设置才能获得更好的调查结果。
央视市场研究个案集群研究部长年来一直承担着国内诸多电视台的栏目观众满意度的评价工作,在问卷中我们根据调查目的和对象的不同,一般使用五分制、十分制与百分制让观众对栏目的满意度进行打分,但哪种量表针对电视节目的满意度调查更为有效,尚未做过系统性的对比分析研究,本文选取2014年1-4月有播出的各卫星频道热门节目30个采用不同量表对观众进行了满意度调查,以下的分析将应用这些采集到的数据围绕下述四个问题进行探讨,用以了解各个量表的特点和差异,并进而得出在电视节目的满意度调查中,使用哪种量表最为有效。
(1) 观众对四种量表的打分特点是什么?四个量表所采集到的数据分布上是否存在统计学差异;
(2)四种量表区分度研究:意在了解各量表在同一个评价对象上是否能有效的区分开评价高的人与评价低的人;
(3)四种量表稳定性研究:分析各量表在不同多次调查中的数据稳定性,以便发现稳定性最高的量表;
(4)四种量表敏感度研究:针对多个电视节目,判断哪种量表更能在统计学意义上分辨出各节目的差异,便于电视台做节目排名使用。
2 研究设计及研究方法
本研究随机选取当前卫星频道较为热门的30个电视节目(见表1),在全国范围内分别以5分、7分、10分和百分量表对观众进行了满意度的数据采集,调查共设计了ABCD四类问卷,每类问卷对应一种量表,如A类问卷对应5分量表,B类问卷对应7分量表,C类问卷对应10分量表,D类问卷对应百分量表。调查采取访员随机入户问卷调查的方式,抽样范围为全国406个区县中的186个样本点,每个样本点样本量为4或4的倍数,ABCD四类问卷在每个样本点循环使用。全国设计访问量为12000,即每类问卷设计样本量为3000,调查执行时间为2014年5月15日到6月15日,共回收有效样本A卷3170份,B卷3145份,C卷3099份,D卷3106份,总计12520份。
表1 本文研究的30个热门电视节目
|
编号
|
节目名称
|
频道
|
编号
|
节目名称
|
频道
|
|
1
|
出彩中国人
|
CCTV-1综合
|
16
|
快乐大本营
|
湖南卫视
|
|
2
|
梦想合唱团
|
CCTV-1综合
|
17
|
我是歌手
|
湖南卫视
|
|
3
|
舌尖上的中国第二季
|
CCTV-1综合
|
18
|
天天向上
|
湖南卫视
|
|
4
|
中国谜语大会
|
CCTV-1综合
|
19
|
我们都爱笑
|
湖南卫视
|
|
5
|
寻找最美系列
|
CCTV-1综合
|
20
|
花儿与少年
|
湖南卫视
|
|
6
|
嗨2014
|
CCTV-1综合
|
21
|
最强大脑
|
江苏卫视
|
|
7
|
中国好歌曲
|
CCTV-3综艺
|
22
|
非诚勿扰
|
江苏卫视
|
|
8
|
中国汉字听写大会
|
CCTV-10科教
|
23
|
金牌调解
|
江西卫视
|
|
9
|
中国成语大会2014
|
CCTV-10科教
|
24
|
中国达人秀
|
上海东方卫视
|
|
10
|
超级演说家
|
安徽卫视
|
25
|
笑傲江湖
|
上海东方卫视
|
|
11
|
养生堂
|
北京卫视
|
26
|
年代秀
|
深圳卫视
|
|
12
|
梨园春
|
河南卫视
|
27
|
非你莫属
|
天津卫视
|
|
13
|
成语英雄
|
河南卫视
|
28
|
中国梦想秀
|
浙江卫视
|
|
14
|
爸爸去哪儿
|
湖南卫视
|
29
|
中国好舞蹈
|
浙江卫视
|
|
15
|
超级演说家
|
安徽卫视
|
30
|
爸爸回来了
|
浙江卫视
|
目前国内外学者对量表精度的检验,最常用到且有效的方法是信度、效度检验。其中信度通过内部一致性系数、折半系数、相关系数、、方差比例系数等方法来检验;效度则分为校标效度、结构效度、内容效度,通过探索性因子分析(EFA)、验证性因子分析(CFA)、结构方程模型等方法进行验证。
由于本文研究电视节目满意度,每个节目满意度问题只有一个,且30个节目满意度之间相互独立,因此上述传统的信度、效度、相关系数等传统检验量表精度的方法在本研究中均不合适。本文针对上述四个研究问题,采用相应的研究方法如下:
(1)通过非参数K-S、偏度、峰度等参数值判断观众用四种量表的打分特点,以及数据在分布上是否存在显著差异,另外通过比较四种量表在中间点比例是否存在显著差异来判断四种量表在数据上的离散程度。
(2)四种量表区分度研究。通过项目分析方法,将每个节目满意度数据按升序排列,分别选取前后27%数据作为高分组和低分组,通过独立样本T检验进行差异检验,并通过t统计量比较四种量表在高低组别上的区分度;
(3)四种量表稳定性研究。将本次各节目在四种量表的数据作为一个样本总体,首先通过随机数(RV.Uniform)将样本总体分为两组,再通过bootstrap随机抽取1500份作为子样本,接下来通过两方面进行稳定性验证:1)检验子样本中两组数据在30个节目满意度均值是否存在统计学差异:2)计算子样本中两组数据在30个节目满意度上的pearson相关系数。将上述步骤在软件中循环重复100次,统计每次的检验结果,进而对比四种量表的稳定性。
(4)四种量表敏感度研究。对特定数量电视节目(本研究为30个节目),通过独立样本均值差异t统计量,计算四种量表在0.05显著性水平下最小均值差,进而判断哪种量表在统计学意义上可以更好的对电视台节目的满意度进行排名,以更好的服务于电视台对于节目的考核与管理。
3 四种量表数据对比研究
3.1 四种量表数据分布研究
3.1.1数据正态分布检验
与前人在满意度调查的数据分布特征上一致,四种量表均不符合正态分布,均呈现明显的左偏,。另外,5分和7分量表的峰度均小于0,说明两种量表数据分布更扁平,即平阔峰;而10分和100分量表刚好相反,分布更陡峭,属于尖峭峰。说明人们在10分和100分量表上,更倾向选择量表中的峰值点
表2 四种量表中30个节目在各指标上的描述统计(均值±标准差)
|
量表种类
|
样本量
|
标准差
|
偏度
|
峰度
|
K-S Z值
|
|
5分
|
496.67±357.83
|
0.77±0.05
|
-0.64±0.24
|
-0.04±0.58
|
5.50±2.23
|
|
7分
|
494.07±355.19
|
1.08±0.06
|
-0.67±0.20
|
-0.02±0.41
|
4.68±1.81
|
|
10分
|
486.47±332.83
|
1.54±0.09
|
-0.74±0.17
|
0.48±0.49
|
3.93±1.47
|
|
100分
|
480.20±351.88
|
13.47±1.66
|
-3.16±0.62
|
15.50±4.85
|
3.60±1.43
|
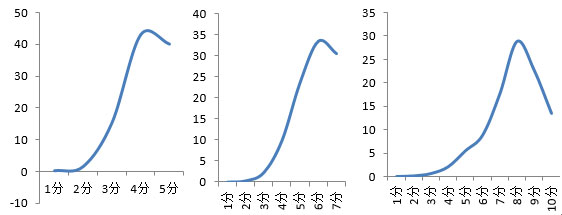
图1 5分、7分和10分量表各分值上的平均比例(%)
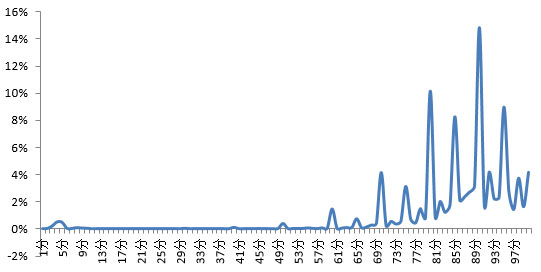
图2 100分量表各分值上的平均比例(%)
3.1.2、中间点比例分布差异检验
对于量表中间点的设计,研究者一直存在争论。多数研究者希望能获得调查对象明确的态度或行为频次,而不是类似于“不同意也不反对”、“一般”等模棱两可的选项,但没有中性中间点会使某些调查对象被迫选择不适合自己情况的其他选项;而设置中间点又增加不认真作答的调查对象选择这一选项的倾向,或调查对象对某些敏感问题不愿表达自己想法时的选择。2008年美国学者John
等研究发现,中性中间点对量表的信度和效度没有影响,并建议设置中性中间点,让调查对象在其他选项不适合自己时有所选择。另外,早在1972年Matell等的研究发现,随着量表等级增加,调查对象选择中间点的比例有所下降,3级和5级时,平均有20%的调查对象选择中间点,而7级、9级到19级时,只有7%的调查对象选择中间点。因此,可通过增加量表等级来减小中性中间点带来的误差。
在本研究中的四种量表都有中间点,因此可以通过比较四种量表的中间点比例来检验四种量表在中间点上带来的误差大小。在检验之前,首先将四种量表数据为五个分值段:低分段、中低分段、中间分段、中高分段和高分段,五个分值段在四种量表分别对应的区间如下表:
表3 四种量表五档分值上的分布区间
|
量表种类
|
低分
|
中低分
|
中间分
|
中高分
|
高分
|
|
5分
|
1
|
2
|
3
|
4
|
5
|
|
7分
|
1
|
2-3
|
4
|
5-6
|
7
|
|
10分
|
1-2
|
3-4
|
5-6
|
7-8
|
9-10
|
|
100分
|
0-19
|
20-49
|
50-69
|
70-89
|
90-100
|
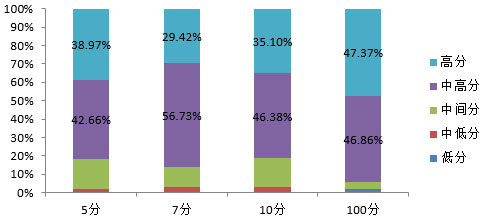
图3 四种量表各分值段的平均比例分布
经检验发现,100分量表的中间点被选比例最低(p<0.05),其次是7分量表,而5分量表和10分量表在中间点比例上无明显差异(p>0.05)。另外,在四个量表中,只有100分量表的数据分布比例最高出现在90-100高分段,而其他三个量表都出现在中高分段。
综合来看,虽然100分量表的中间点比例最低,但是100分量表都集中在中高分和高分段(如表5),在数据分布上失去了量表低分和中低分段的意义。因此7分量表中间点被选比例最低,并且7分量表中高分比例在四种量表中比例最高,
表4 四种量表中间点比例
|
|
5分量表
|
7分量表
|
10分量表
|
100分量表
|
|
均值
|
16.36%
|
10.75%
|
15.30%
|
4.10%
|
|
最大值
|
26.00%
(嗨2014)
|
16.95%
(梦想合唱团)
|
21.99%
(中国喜剧星)
|
2.64%
(非诚勿扰)
|
|
最小值
|
8.22%
(最强大脑)
|
5.43%
(中国汉字听写大会)
|
7.99%
(舌尖上的中国)
|
0.10%
(超级演说家)
|
3.2 四种量表区分度研究
本节通过各节目在不同量表得分进行项目分析,检验各量表的区分度。将各节目的样本由低到高排序,分别选取前27%人群作为低分组、后27%人群作为高分组,进行独立样本t检验。结果显示:四种量表在各节目上的高低分均存在非常显著的差异(p<0.05),说明四种量表在各节目的满意度调查上都存在明显的区分度。
接下来比较四种量表在各节目高低分独立样本T检验得到的t值大小,来判断四种量表区分度强弱。配对样本T检验结果显示:四种量表项目分析t值均存在较高的相关性,即某节目在一种量表得分的区分度越高,在其他三种量表得分上的区分度也越高。其中,10分量表与7分量表的相关系数最高,达0.944,说明这两种量表在区分度上变化趋势最一致。
从区分度大小来看,100分量表的区分度明显低于其他三种量表(p<0.05),另外,10分量表的区分度也显著低于7分量表(p<0.05),而5分量表和7分量表之间的区分度不存在显著差异(p>0.05)。因此,从区分度指标来看,5分、7分量表最优,10分量表其次,100分量表最差。
表5 四种量表各节目的项目分析t值绝对值
|
节目
|
100分量表
|
10分量表
|
7分量表
|
5分量表
|
|
Q1
|
23.025
|
22.154
|
27.529
|
16.111
|
|
Q2
|
22.435
|
43.518
|
57.091
|
43.351
|
|
Q3
|
24.112
|
42.576
|
55.647
|
41.341
|
|
Q4
|
15.752
|
28.088
|
28.578
|
36.325
|
|
Q5
|
16.859
|
27.881
|
33.571
|
28.040
|
|
Q6
|
20.408
|
45.601
|
46.107
|
51.047
|
|
Q7
|
8.595
|
20.132
|
19.559
|
28.985
|
|
Q8
|
28.013
|
54.156
|
60.944
|
50.730
|
|
Q9
|
12.928
|
25.940
|
33.028
|
22.961
|
|
Q10
|
26.605
|
52.536
|
67.116
|
45.490
|
|
Q11
|
9.610
|
25.594
|
20.458
|
35.880
|
|
Q12
|
34.990
|
53.479
|
56.524
|
82.500
|
|
Q13
|
12.322
|
25.835
|
28.375
|
27.934
|
|
Q14
|
16.353
|
31.059
|
28.774
|
29.478
|
|
Q15
|
18.892
|
43.627
|
60.636
|
38.839
|
|
Q16
|
14.362
|
31.326
|
32.436
|
32.344
|
|
Q17
|
24.861
|
41.160
|
55.119
|
43.961
|
|
Q18
|
11.261
|
20.253
|
19.964
|
13.863
|
|
Q19
|
16.735
|
36.952
|
48.224
|
32.548
|
|
Q20
|
11.119
|
23.300
|
23.391
|
17.491
|
|
Q21
|
18.406
|
45.092
|
59.611
|
46.239
|
|
Q22
|
14.863
|
35.378
|
44.631
|
32.269
|
|
Q23
|
11.788
|
21.814
|
24.255
|
22.825
|
|
Q24
|
12.273
|
25.582
|
24.373
|
24.176
|
|
Q25
|
14.337
|
30.810
|
31.162
|
45.933
|
|
Q26
|
10.442
|
23.739
|
19.875
|
42.294
|
|
Q27
|
7.015
|
17.231
|
21.435
|
22.333
|
|
Q28
|
13.502
|
34.923
|
32.866
|
28.559
|
|
Q29
|
18.538
|
40.992
|
49.973
|
37.819
|
|
Q30
|
8.327
|
18.220
|
23.590
|
21.372
|
表6 各量表项目分析t值的配对样本t检验结果
|
量表种类
|
均值
|
标准差
|
10分量表
|
7分量表
|
5分量表
|
配对样本T检验两两比较结果
|
|
100分
|
16.624
|
6.598
|
0.857
|
0.819
|
0.733
|
5分、7分、10分>100分,7分>10分
|
|
10分
|
32.965
|
11.009
|
——
|
0.944
|
0.804
|
|
7分
|
37.828
|
15.446
|
——
|
——
|
0.668
|
|
5分
|
34.768
|
13.744
|
——
|
——
|
——
|
注:表中第4-6列为两两量表之间t值的pearson相关系数。
3.3 四种量表稳定性检验
将原有所有节目的样本随机分为两组,对比30个节目在两组中的四种量表得分是否存在显著差异。检验结果显示:5分、7分、10分和100分四种量表出现显著差异的节目数分别为2、4、3、1个(p<0.05)。可见四种量表在30个节目上都出现了显著差异的节目,其中100分量表出现显著差异的节目数相对最少,在一定程度上可反映100分量表相对最稳定。
表7 五分量表独立样本差异检验
|
|
5分量表均值差
|
7分量表均值差
|
10分量表均值差
|
100分量表均值差
|
|
中国谜语大会
|
-0.014
|
-0.202
|
0.26
|
2.415
|
|
我是歌手
|
0.064
|
-0.094
|
0.024
|
-0.521
|
|
舌尖上的中国第二季
|
0.09*
|
-0.064
|
0.002
|
0.604
|
|
花儿与少年
|
0.049
|
-0.014
|
-0.169
|
-0.431
|
|
中国汉字听写大会2013
|
0.052
|
-0.117
|
-0.299*
|
0.981
|
|
天天向上
|
-0.071
|
0.004
|
-0.063
|
1.154
|
|
嗨2014
|
0.14
|
-0.047
|
0.461
|
-2.248
|
|
快乐大本营
|
0.016
|
-0.023
|
0.137
|
-1.256
|
|
中国成语大会2014
|
0.107
|
-0.376*
|
0.384*
|
1.768
|
|
爸爸去哪儿
|
-0.032
|
-0.008
|
-0.076
|
-0.513
|
|
梦想合唱团
|
-0.16
|
-0.231
|
0.083
|
-0.183
|
|
非诚勿扰
|
0.04
|
-0.038
|
-0.078
|
0.791
|
|
中国好舞蹈
|
-0.032
|
0.031
|
0.04
|
0.163
|
|
非你莫属
|
0.05
|
-0.124
|
0.035
|
1.311
|
|
中国好歌曲
|
0.023
|
0.001
|
0.008
|
1.325
|
|
笑傲江湖
|
0.158
|
-0.254*
|
-0.069
|
0.506
|
|
出彩中国人
|
0.003
|
-0.023
|
0.092
|
0.812
|
|
梨园春
|
-0.113
|
0.058
|
0.017
|
2.271
|
|
养生堂
|
-0.04
|
0.049
|
0.208
|
1.175
|
|
寻找最美(乡村医生、孝心少年)系列
|
0.076
|
-0.324*
|
-0.114
|
3.638
|
|
中国达人秀
|
0.04
|
0.073
|
0.12
|
0.95
|
|
金牌调解
|
-0.002
|
-0.011
|
0.039
|
2.777*
|
|
成语英雄
|
0.127
|
-0.083
|
-0.013
|
-0.207
|
|
年代秀
|
-0.084
|
0.069
|
0.318
|
1.495
|
|
爸爸回来了
|
0.053
|
-0.101
|
0.299
|
-2.184
|
|
中国喜剧星
|
-0.03
|
-0.421*
|
-0.585*
|
-0.058
|
|
超级演说家第二季
|
-0.297*
|
-0.251
|
-0.089
|
0.845
|
|
最强大脑
|
0.031
|
0.01
|
-0.015
|
0.252
|
|
中国梦想秀
|
0.096
|
-0.093
|
0.025
|
-1.329
|
|
我们都爱笑
|
0.156
|
0.138
|
-0.156
|
-2.961
|
3.4 四种量表有效性研究
本文的有效性是指两个节目间满意度存在显著差异的均值差。根据调查结果可知,30个节目在四种量表的平均样本量均在480-500之间,为了计算方便,本研究统一取500;标准差统一取四种量表30个节目的平均标准差,根据独立样本均值差异t检验公式:

其中,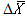 为两个节目间的满意度均值差,S2某个节目满意度得分的标准差,n为样本数。 为两个节目间的满意度均值差,S2某个节目满意度得分的标准差,n为样本数。
为计算四种量表的有效性,本研究假设所计算的两个样本标准差均为量表内30个节目的平均标准差,样本量均为500。因此应采用t检验统计量公式(1)来计算,在自由度为998(500+500-2)时,95%置信区间下的t统计量为1.962344,99%置信区间t统计量为2.580765。在这两个置信区间下分别计算出四种量表对应的敏感度,结果见表17:
表8 四种量表95%和99%两种置信区间下的敏感度
|
量表种类
|
标准差
|
两节目的样本量
|
敏感度(p=0.05)
|
敏感度(p=0.01)
|
|
5分
|
0.765
|
100
|
0.24393
|
0.32171
|
|
300
|
0.14025
|
0.18454
|
|
500
|
0.10855
|
0.14276
|
|
1000
|
0.07671
|
0.10085
|
|
1500
|
0.06262
|
0.08232
|
|
2000
|
0.05423
|
0.07128
|
|
7分
|
1.077
|
100
|
0.28942
|
0.38172
|
|
300
|
0.16641
|
0.21896
|
|
500
|
0.12880
|
0.16939
|
|
1000
|
0.09102
|
0.11966
|
|
1500
|
0.07430
|
0.09767
|
|
2000
|
0.06434
|
0.08457
|
|
10分
|
1.541
|
100
|
0.34620
|
0.45660
|
|
300
|
0.19906
|
0.26192
|
|
500
|
0.15407
|
0.20262
|
|
1000
|
0.10887
|
0.14314
|
|
1500
|
0.08888
|
0.11683
|
|
2000
|
0.07696
|
0.10116
|
|
100分
|
13.471
|
100
|
1.02359
|
1.35001
|
|
300
|
0.58855
|
0.77439
|
|
500
|
0.45552
|
0.59907
|
|
1000
|
0.32190
|
0.42320
|
|
1500
|
0.26278
|
0.34543
|
|
2000
|
0.22755
|
0.29911
|
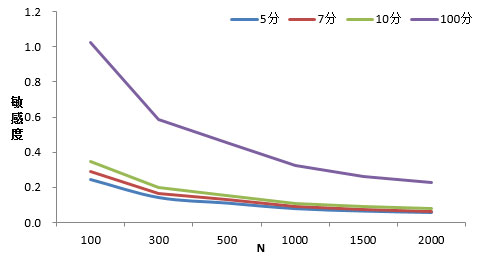
图4 四种量表不同样本量下95%置信区间的敏感度
结果可见,在0.05显著性水平下,5分、7分、10分和100分四种量表两个节目之间存在显著差异的满意度均值差分别为0.108582、0.128780、0.154045和0.455521。居于此,结合四种量表极差值(最大值-最小值),将四种量表分成多个敏感度组别,即每个组别间的节目存在满意度显著差异,而每个组别内的节目满意度不存在显著差异。敏感度组别数计算公式为:
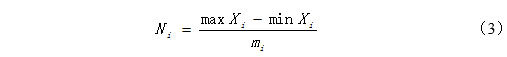
Xi表示第i种量表的各节目满意度均值,mi表示第i种量表的敏感度。经计算,5分、7分、10分和100分四种量表可划分的敏感度组别数分别为5、6、7和16组。从30个节目在四种量表的敏感度组别分布情况可以看出,100分量表可以更加精细化调查出每个节目的满意度,每个敏感度组别中的节目数最少,调查精度最高。
表9 四种量表95%和99%两种置信区间下的敏感度
|
量表种类
|
极小值
|
极大值
|
敏感度(p=0.05)
|
敏感度组别数
|
|
5分
|
3.90
|
4.45
|
0.108582
|
5
|
|
7分
|
5.43
|
6.17
|
0.12878
|
6
|
|
10分
|
7.31
|
8.37
|
0.154045
|
7
|
|
100分
|
82.28
|
89.65
|
0.455521
|
16
|
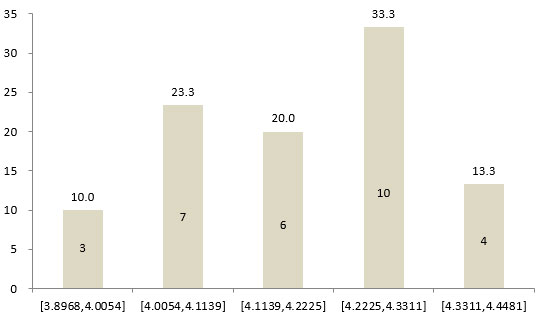
图5 30个节目在5分量表各敏感度组别内的节目占比(%)
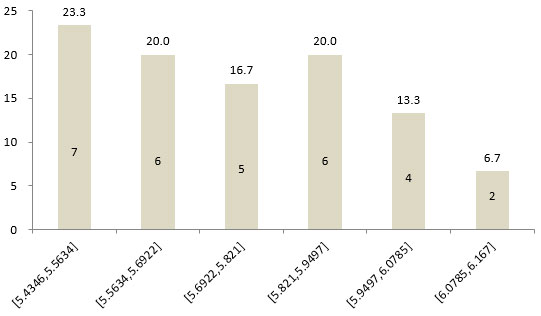
图6 30个节目在7分量表各敏感度组别内的节目占比(%)
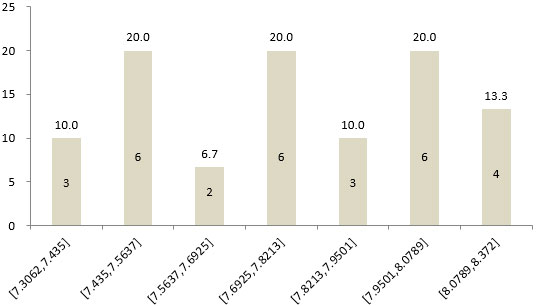
图7 30个节目在10分量表各敏感度组别内的节目占比(%)
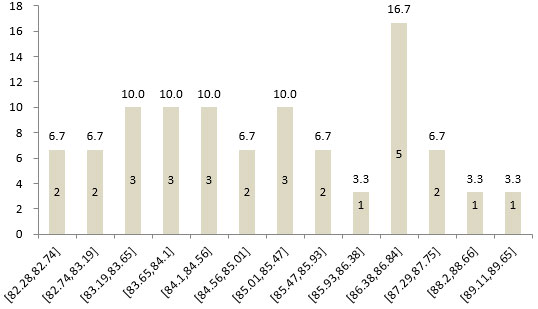
图8 30个节目在100分量表各敏感度组别内的节目占比(%)
4 总结与讨论
从上述分析可以基本看出,在电视节目满意度调查中,5分、7分、10分和100分四种量表的数据均具有效度。
在数据分布上,100分量表在抽样误差随样本量减小的速度明显不如其他三个量表。100分量表在中高分段和高分段上比例明显高于其他三个量表, 7分量表的中间点比例相对5分、10分量表最低,中间点带来的误差最小。
人们对节目满意度评价越低,在5分、7分和10分量表选择中间分的概率会越高,而在100分量表中选择中高分的概率最高;另外随着人们的满意度分值越低,7分量表中选择中低分段的概率是四种量表中最高的。
从量表区分度来看,100分量表最低,其次是10分量表,7分量表比5分量表略高。表明100分量表对观众两个极端态度的评价上最差。这与人们不怎么选择百分制下的中低分段是直接相关的。
|







